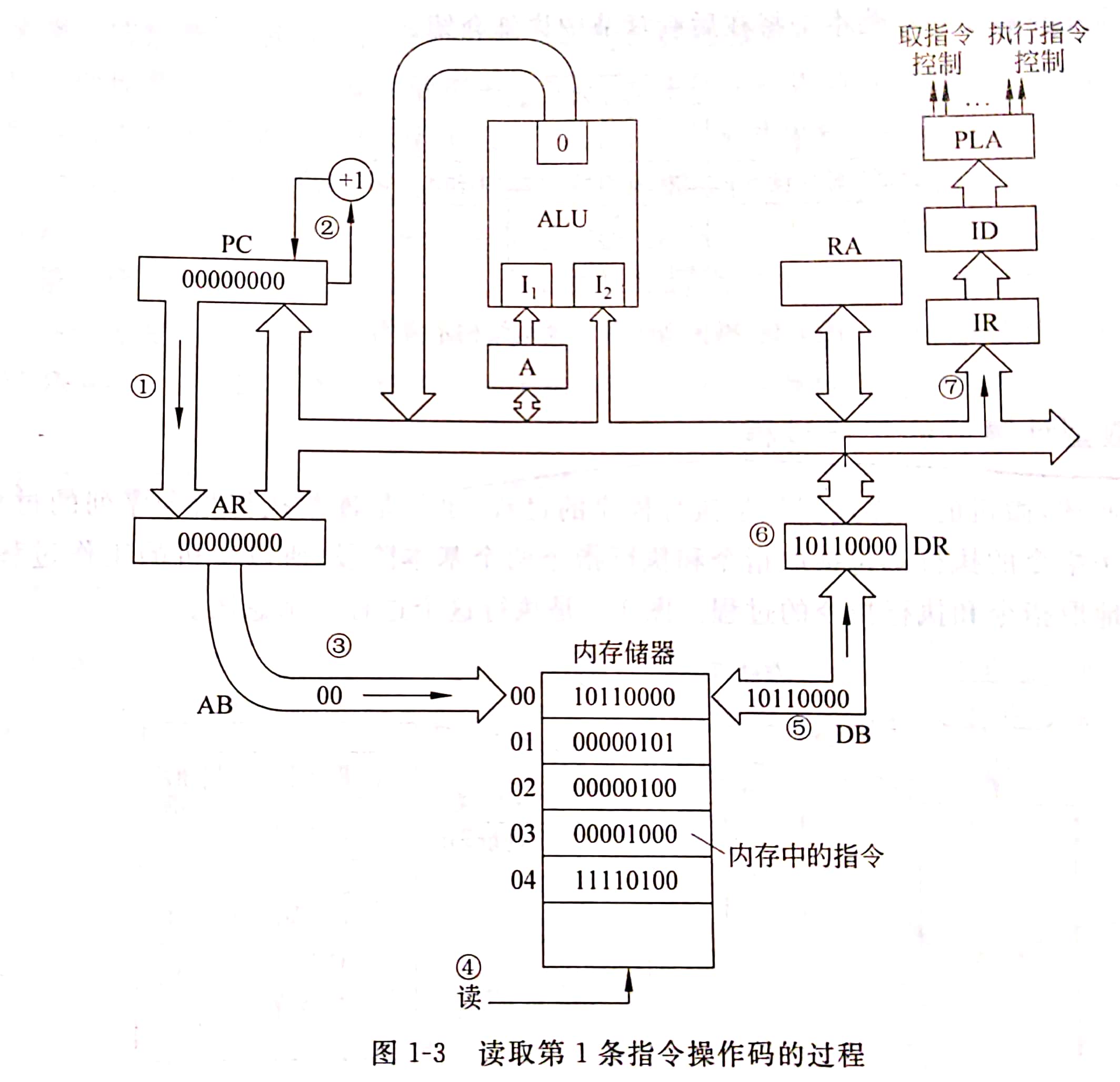
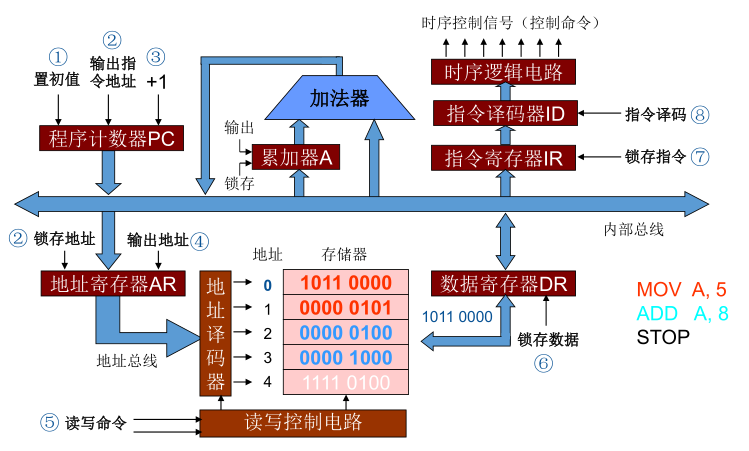
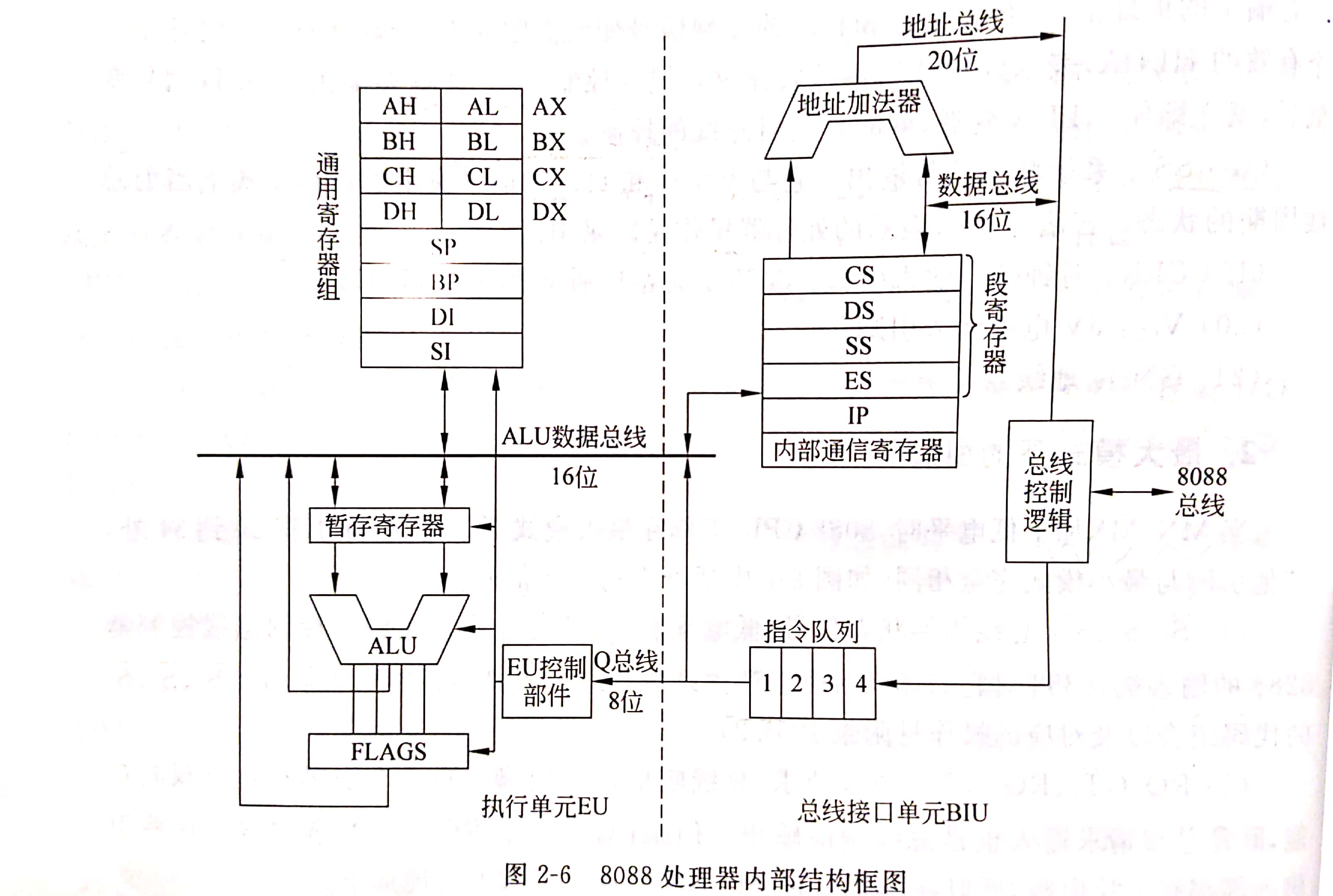
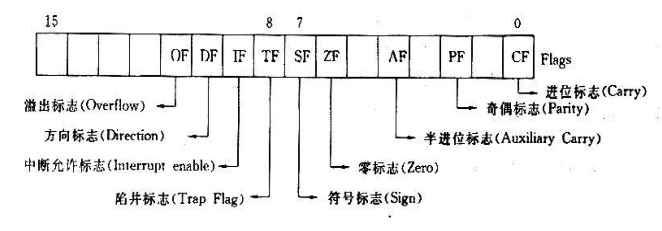
概率论的基本概念
随机试验
样本空间、随机事件
样本空间
- 定义
随机试验E的所有可能结果所组成的集合称为样本空间,记为S
样本空间的元素,即E的每个结果,称为样本点
随机事件
事件关系的运算
频率与概率
频率
概率
等可能概型(古典概型)
条件概率
定义
一般地,设A、B是S中的两个事件,若$P(A)>0$,则
称为在事件A发生的条件下事件B发生的条件概率
性质
条件概率$P(\cdot|A)$符合概率定义中的三个条件
- 非负性:对任一事件B,有$P(B|A)\geq 0$
- 规范性:对于样本空间S,有$P(S|A)=1$
- 可列可加性:设$B_1,B_2\dotsm$是两两互斥事件,则
乘法定理
- 设$P(A)>0$,则有
- 设$P(AB)>0$,推广
- 一般地,设$A1,A_2,\dotsm,A_n$为n个事件,$n\geq 2$,且$P(A_1A_2\dotsm A{n-1})>0$,则有
划分
设S为试验E的样本空间,$B_1,B_2,\dotsm B_n$为E的一组事件,若
- $B_iB_j=\phi, i\neq j,~~i,j=1,2,\dotsm,n$
- $B_1\cup B_2\cup\dotsm\cup B_n=S$
则称$B_1,B_2,\dotsm B_n$为样本空间的一个划分
全概率公式
设试验E的样本空间为S,A为E的事件,$B_1,B_2,\dotsm B_n$为S的一个划分,且$P(B_i)>0~(i=1,2,\dotsm,n)$,则全概率公式为
贝叶斯公式
设试验E的样本空间为S,A为E的事件,$B_1,B_2,\dotsm B_n$为S的一个划分,且$P(B_i)>0~(i=1,2,\dotsm,n)$,则贝叶斯公式为
总结
- 条件概率是求事件A发生条件下事件B发生的概率
- 乘法公式是求“几个事件同时发生”的概率
- 全概率公式是求“最后结果”的概率
- 贝叶斯公式是已知“最后结果”,求“原因”的概率
独立性
定义
设A,B是两个事件,如果满足等式
则称事件A、B相互独立,简称A、B独立
相互独立与互不相容的区分
- A、B相互独立 $\Longrightarrow P(AB)=P(A)P(B)$
- A、B互不相容 $\Longrightarrow AB=\phi \Longrightarrow P(AB)=0$
若$P(A)>0,P(B)>0$则A、B相互独立与A、B互不相容不能同时成立
定理一
设A、B是两事件,且$P(A)>0$,若A、B相互独立,则$P(B|A)=P(B)$反之亦然
定理二
设A、B是两事件,若A、B相互独立,则$A与\overline{B},\overline{A}与B,\overline{A}与\overline{B}$都相互独立
多事件相互独立
一般地,设$A_1,A_2,\dotsm,A_n (n\geq2)$个事件,如果对其中任意2个,3个,$\dotsm$,n个事件的积事件概率,都等于各事件概率之积,则称事件$A_1,A_2,\dotsm,A_n$相互独立
推论
若事件$A_1,A_2,\dotsm,A_n (n\geq2)$相互独立
- 其中任意$k(2\leq k\leq n)$个事件也是相互独立的
- 则将$A_1,A_2,\dotsm,A_n$中任意多个换成它们的对立事件,所得的n个事件仍然相互独立
随机变量及其分布
随机变量
- 定义
设$X=X(e)$是定义在样本空间S上的单值实值函数,称$X=X(e)$为随机变量
随机变量通常用大写字母$X,Y,Z,W\dotsm$等表示
一般地,若L是一个实数集合,将X在L上取值写成${X\in L}$,它表示事件$A={e|X(e)\in L}$,即A是由S中使得$X(e)\in L$的所有样本点e所组成的事件,此时有
离散型随机变量及其分布律
离散型随机变量的定义
随机变量的全部可能取值是有限个或者可列无限个,这种随机变量称为离散型随机变量
分布律
设$X$所有可能取的值为$x_k(k=1,2,\dotsm)$,而
$p_k$满足如下两个条件
- $p_k\geq 0, ~k=1,2,\dotsm$
- $\sum_{k=1}^{\infty}p_k=1$
分布律也可以用表格表示
$X$|$x_1$|$x_2$|$\dotsm$|$x_n$|$\dotsm$
:-:|:-:|:-:|:-:|:-:|:-:
$p_k$|$p_1$|$p_2$|$\dotsm$|$p_n$|$\dotsm$
(0-1)分布
设随机变量$X$只可能取0与1两个值,则称$X$服从$(0-1)$分布或两点分布,它的分布律是
| $X$ |
$x_1$ |
$x_2$ |
| $p_k$ |
$1-p$ |
$p$ |
二项分布
- 伯努利试验
设试验$E$只有两个可能结果:$A$及$\overline{A}$,则称$E$为伯努利试验
设$P(A)=p~~~(0<p<1)$,此时$P(\overline{A})=1-p$
将$E$独立地重复进行n次试验,则称这一串重复的独立试验为n重伯努利试验
n重伯努利试验即为二项分布
- 二项分布
设随机变量$X$服从参数为$n,p$的二项分布,记作$X\sim B(n,p)$则
泊松分布
设随机变量$X$所有可能的值为$0,1,2,\dotsm$,而取各个值的概率为
其中$\lambda>0$是常数,则称$X$服从参数为$\lambda$的泊松分布,记为$X\sim \pi(\lambda)$
总结
- 二项分布$\xrightarrow{n=1}$两点分布
- 二项分布$\xrightarrow{np\rightarrow\lambda(n\rightarrow\infty)}$泊松分布
- 二项分布$\xrightarrow{n\rightarrow\infty}$正态分布
- 二项分布中,当n很大,p很小时,可近似为
随机变量的分布函数
一般地,设离散型随机变量$X$的分布律为
分布函数$F(x)$在$x=x_k(k=1,2,\dotsm)$处有跳跃,其跳越值为$p_k=P{X=x_k}$
连续型随机变量及其概率密度
均匀分布
设连续型随机变量$X$具有概率密度
则称$X$在区间$(a,b)$上服从均匀分布,记为$X\sim U(a,b)$
其分布函数为
指数分布
设连续型随机变量$X$具有概率密度
其中$\theta>0$为常数,则称$X$服从参数为$\theta$的指数分布
$X$的分布函数为
- $X$服从指数分布,则任给$x,t>0$,有
该性质称为无记忆性
正态分布
设连续型随机变量$X$具有概率密度
其中$\mu, \sigma(\sigma>0)$为常数,则称$X$服从参数为$\mu,\sigma$的正态分布或高斯分布,记为$X\sim N(\mu, \sigma^2)$
$X$的分布函数为
性质
- 曲线关于$x=\mu$对称
- 当$x=\mu$时取到最大值
- $x$离$\mu$越远,$f(x)$的值越小
- 在$x=\mu\pm\sigma$处曲线有拐点
- 曲线以$Ox$轴为渐近线
标准正态分布
特别地,称$N\sim(0,1)$为标准正态分布,其概率密度函数和分布函数常分别用$\varphi(x)$和$\varPhi(x)$表示
任何一个一般的正态分布都可以转化为标准正态分布,即
若$X\sim N(0,1)$,则
- $\varPhi(-x)=1-\varPhi(x)$
- $P{a<X<b}=\varPhi(b)-\varPhi(a)$
上$\alpha$分位点
设$X\sim N(0,1)$,若$z_\alpha$满足条件
则称点$z\alpha$为标准正态分布的上$\alpha$分位点,可知$z{1-\alpha}=-z_\alpha$

随机变量的函数的分布
定义
已知随机变量$X,Y$,$X$的分布律(概率密度)已知,$Y=g(X)$,$g$为连续函数,则随机变量$Y$的分布就称为随机变量$X$的函数的分布
离散型
若随机变量$X$为离散型,则直接代入计算$Y$的分布律,若有值相同的,合并即可
连续型
设随机变量$X$具有概率密度$f_X(x)$,其中$-\infty<x<+\infty$,设函数$g(x)$处处可导,且恒有$g’(x)>0$(或恒有$g’(x)<0$),则$Y=g(X)$也是连续型随机变量,其概率密度为
其中$\alpha=min(g(-\infty), g(+\infty)),\beta=max(g(-\infty), g(+\infty)),h(y)$是$g(x)$的反函数
多维随机变量及其分布
二维随机变量
定义
设$E$是一个随机试验,其样本空间为$S={e}$,设$X=X(e)$和$Y=Y(e)$是定义在$S$上的随机变量,由它们构成的一个向量$(X,Y)$,叫做二维随机向量或二维随机变量
联合分布函数
设$(X,Y)$是二维随机变量,对于任意实数$x,y$,二元函数: 称为二维随机变量$(X,Y)$的分布函数,或称为随机变量$X$和$Y$的联合分布函数

分布函数的性质
- $F(x,y)$是变量$x,y$的不减函数
- $0\leq F(x,y)\leq 1$
- $F(x,y)=F(x+0,y),F(x,y)=F(x,y+0)$
二维离散型随机变量
定义
若二维随机变量$(X,Y)$全部可能取到的值的有限对或者可列无限多对,则称$(X,Y)$为二维离散型随机变量
分布律
设二维随机变量$(X,Y)$所有可能取的值为$(X_i,y_i),~i,j=1,2,\dotsm$,记
称上式为二维离散型随机变量$(X,Y)$的分布律,或随机变量$X$和$Y$的联合分布律,其中
分布函数
二维离散型随机变量的$(X,Y)$的分布函数为
上式是对一切满足$x_i\leq x,y_i\leq y$的$i,j$求和
二维连续型随机变量
定义
对于二维随机变量$(X,Y)$的分布函数$F(x,y)$,如果存在非负可积的函数$f(x,y)$使对于任意$x,y$有
则称$(X,Y)$是二维连续型随机变量,函数$f(x,y)$称为二维随机变量$(X,Y)$的概率密度,或称为随机变量$X$和$Y$的联合概率密度
性质
- $f(x,y)\geq 0$
- $\int{-\infty}^{+\infty}\int{-\infty}^{+\infty}f(x,y)dxdy=F(\infty,\infty)=1$
- 设$G$是$xOy$平面上的一个区域,点$(X,Y)$落在$G$内的概率为
- 若$f(x,y)$在$(x,y)$连续,则有$\frac{\partial^2F(x,y)}{\partial x \partial y}=f(x,y)$
边缘分布
边缘分布函数
二维随机变量$(X,Y)$作为一个整体,具有分布函数$F(x,y)$,而$X$和$Y$都是随机变量,也有各自的分布函数,分别记为$F_X(x),F_Y(y)$,依次称为二维随机变量$(X,Y)$关于$x,y$的边缘分布函数
离散型随机变量的边缘分布
设二维离散型随机变量$(X,Y)$的联合分布律为
记
分别称$p{i\cdot}$和$p{\cdot j}$为$(X,Y)$关于$X$和关于$Y$的边缘分布律
连续型随机变量的边缘分布
对于连续性随机变量$(X,Y)$,设它的概率密度为$f(x,y)$,则$X,Y$的边缘分布和边缘概率密度为
- 均匀分布
设$G$是平面上的有界区域,其面积为$A$,若二维随机变量$(X,Y)$具有概率密度则称$(X,Y)$在$G$上服从均匀分布
- 正态分布
太长了。。。就不写了
条件分布
设有两个随机变量$X,Y$,在$Y$取某个值或某些值的情况下,$X$的概率分布即为条件概率
二维离散型随机变量的条件分布
设$(X,Y)$是二维离散型随机变量,对于固定的$j$,若$P{Y=y_i}>0$,则称
为在$Y=y_i,i=1,2,\dotsm$条件下随机变量$X$的条件分布律
同理,在$X=x_i,i=1,2,\dotsm$条件下随机变量$Y$的条件分布律为
二维连续型随机变量的条件分布
设二维随机变量$(X,Y)$的概率密度为$f(x,y),~(X,Y)$关于$Y$的边缘概率密度为$f_Y(y)$,若对于固定的$y$,$f_Y(y)>0$,则$Y=y$的条件下$X$的条件概率密度为
条件分布函数为
同理,在$X=x$的条件下$Y$的条件概率密度为
条件分布函数为
相互独立的随机变量
定义
设$F(x,y)$及$F_X(x),F_Y(y)$分别是二维随机变量$(X,Y)$的分布函数及边缘分布还是。若对于所有的$x,y$有
即
则称随机变量$X,Y$是相互独立的。
离散型随机变量
若离散型随机变量$X$和$Y$的联合分布律为
$X$和$Y$相互独立$\Leftrightarrow P{X=xi, Y=y_j}=P{X=x_i}{Y=y_j}\Leftrightarrow p{ij}=p{i\cdot}p{\cdot j}$
- 连续型随机变量
设$(X,Y)$是二维连续型随机变量,具有概率密度为$f(x,y)$,边缘概率密度分别为$f_X(x),f_Y(y)$。
$X$和$Y$相互独立$\Leftrightarrow f(x,y)=f_X(x)f_Y(y)$
两个随机变量的函数的分布
$Z=X+Y$的分布
设$(X,Y)$是二维连续型随机变量,具有概率密度为$f(x,y)$,则$Z=X+Y$的概率密度为
若$X$和$Y$独立,设$(X,Y)$关于$X,Y$的边缘概率密度为$f_X(x),f_Y(y)$,则
上式称为卷积公式
若$X_i\sim N(\mu_i, \sigma_i^2), i=1,2,\dotsm$,则
$M=max(X,Y)$和$N=min(X,Y)$的分布
设$X$和$Y$是两个相互独立的随机变量,它们的分布函数分别为$F_X(x)$和$F_Y(y)$,则$M=max(X,Y)$和$N=min(X,Y)$的分布函数为
随机变量的数字特征
数学期望
离散型随机变量的数学期望
设$X$是离散型随机变量,它的分布律为
若级数$\sum{k=1}^\infty x_kp_k$绝对收敛,则级数$\sum{k=1}^\infty x_kp_k$的和为随机变量$X$的数学期望,简称期望,又称为均值
连续型随机变量的数学期望
设$X$是连续型随机变量,其概率密度函数为$f(x)$,如果积分
绝对收敛,则称此积分值为$X$的数学期望,即
随机变量的函数的数学期望
设$Y$是随机变量$X$的函数:$Y=g(X)$($g$是连续函数)
当$X$为连续型时,它的分布律为$P{X=xk}=p_k,~(k=1,2,\dotsm)$,若$\sum{k=1}^\infty g(x_k)p_k$绝对收敛,则有
当$X$为连续型时,它的概率密度为$f(x)$,若$\int_{-\infty}^{+\infty} g(x)f(x)dx$绝对收敛,则有
数学期望的性质
- 设$C$为常数,则$E(C)=C$
- 设$k$为常数,则$E(kX)=kE(X)$
- $E(X+Y)=E(X)+E(Y)$
- 设$X$和$Y$相互独立,则$E(XY)=E(X)E(Y)$
方差
定义
设$X$是一个随机变量,若$E([X-E(X)]^2)$存在,称$E([X-E(X)]^2)$为$X$的方差。记为$D(X)$或$Var(X)$,即
方差的算术平方根$\sqrt{D(X)}$称为$X$的标准差或均方差,记为$\sigma(X)$
计算
由定义知,方差是随机变量$X$的函数$g(X)=[X-E(X)]^2$的数学期望
离散型
若$X$是离散型随机变量,它的分布律为$P{X=x_k}=p_k,~k=1,2,\dotsm$,则
连续型
若$X$为连续型时,它的概率密度为$f(x)$,则
性质
- 设$C$为常数,则$D(C)=0, D(X+C)=D(X)$
- 设$k$为常数,则$D(kX)=k^2D(X)$
- $D(X+Y)=D(X)+D(Y)+2E([X-E(X)][Y-E(Y)])$
- $D(X)=0 \Leftrightarrow P{X=C}=1$,这里$C=E(X)$
- 设$X$和$Y$相互独立,则$D(X+Y)=D(X)+D(Y)$
| 分布 |
参数 |
数学期望 |
方差 |
| 两点分布 |
$0<p<1$ |
$p$ |
$p(1-p)$ |
| 二项分布 |
$n\geq 1,0<p<1$ |
$np$ |
$np(1-p)$ |
| 泊松分布 |
$\lambda>0$ |
$\lambda$ |
$\lambda$ |
| 均匀分布 |
$a<b$ |
$(a+b)/2$ |
$(b-a)^2/12$ |
| 指数分布 |
$\theta>0$ |
$\theta$ |
$\theta^2$ |
| 正态分布 |
$\mu, \sigma>0$ |
$\mu$ |
$\sigma^2$ |
切比雪夫不等式
设随机变量$X$具有数学期望$E(X)=\mu$,方差$D(X)=\sigma^2$,则对于任意正数$\varepsilon$,有不等式
由切比雪夫不等式可以看出,若$\sigma^2$越小,则事件${|X-E(X)|\geq \varepsilon}$的概率越大
协方差及相关系数
协方差
相关系数
矩、协方差矩阵
原点矩、中心矩
设$X$和$Y$是随机变量,若
存在,称它为$X$的$k$阶原点矩,简称$k$阶矩
若
存在,称它为$X$的$k$阶中心距
可见,均值$E(X)$是$X$的$k$阶中心矩,方差$D(X)$是$X$的二阶中心矩
协方差矩阵(不考)
大数定律及中心极限定理
大数定律
- 背景
大量随机试验中,事件发生的频率稳定于某一常数,测量值的算术平均值具有稳定性
- 概念
概率论中用来阐明大量随机现象平均结果的稳定性的一系列定理,称为大数定律
依概率收敛
定义
设$Y_1,Y_2,\dotsm,Y_n\dotsm$是一个随机变量序列,$a$是一个常数。若对于任意正数$\varepsilon$,有
则称序列$Y_1,Y_2,\dotsm,Y_n\dotsm$依概率收敛于$a$,记为
性质
设$X_n\xrightarrow{P}a,Y_n\xrightarrow{P}b$,设函数$g(x,y)$在点$(a,b)$连续,则
总结
设随机变量$X_1,X_2,\dotsm,X_n,\dotsm$相互独立
| 大数定律 |
表达式 |
条件 |
| 伯努利大数定律 |
|
|
| 切比雪夫大数定律 |
|
|
| 辛钦大数定律 |
|
|
$abs()$代表绝对值
中心极限定理
独立同分布下的中心极限定理
设随机变量$X1,X_2,\dotsm,X_n,\dotsm$相互独立,服从同一分布,具有数学期望和方差:$E(X_k)=\mu,D(X_k)=\sigma^2,(k=1,2,\dotsm)$,则随机变量之和$\sum{k=1}^n X_k$的标准化变量的分布函数为$F_n(x)$对于任意$x$满足
李雅普诺夫定理
设随机变量$X1,X_2,\dotsm,X_n,\dotsm$相互独立,服从同一分布,具有数学期望和方差:$E(X_k)=\mu_k,D(X_k)=\sigma^2_k,(k=1,2,\dotsm)$,记$B_n^2=\sum{k=1}^n\sigmak^2$,则随机变量之和$\sum{k=1}^n X_k$的标准化变量的分布函数为$F_n(x)$对于任意$x$满足
棣莫弗-拉普拉斯定理
设随机变量$\eta_n(n=1,2,\dotsm)$服从参数$n,p(0<p<1)$的二项分布,对于任意$x$有
定理表明,当$n$很大,$0<p<1$是一个定值时,二项分布的随机变量的$\eta_n$分布近似正态分布$N(np,np(1-p))$.
样本及抽样分布
随机样本
总体与个体
- 研究对象的全体称为总体
- 总体中每个成员称为个体
- 总体中所包含的个体的个数称为总体的容量
样本
- 总体中抽出若干个体而成的的集体,称为样本
- 样本所含个体的个数,称为样本容量
抽样分布